Abstract
Numerical voice impression (VI) control (e.g., scaling brightness) enables fine-grained control in text-to-speech (TTS). However, it faces two challenges: no public corpus and impression leakage, where reference audio biases synthesized voice away from the target VI. To address the first challenge, we introduce LibriTTS-VI, the first public VI corpus built on LibriTTS-R. For the second, we hypothesize a single reference causes leakage by entangling speaker identity and VI. To mitigate this, we propose 1) disentangled training with two utterances from the same speaker for speaker and VI conditioning, and 2) a reference-free method controlling the impression solely via target VI. Experimentally, our best method improves controllability: 11-dimensional VI mean squared error drops from 0.61 to 0.41 objectively and 1.15 to 0.92 subjectively. A comparison with a prompt-based TTS reveals imprecise numerical control and entanglement between VI and text semantics, which our methods overcome.
Overview
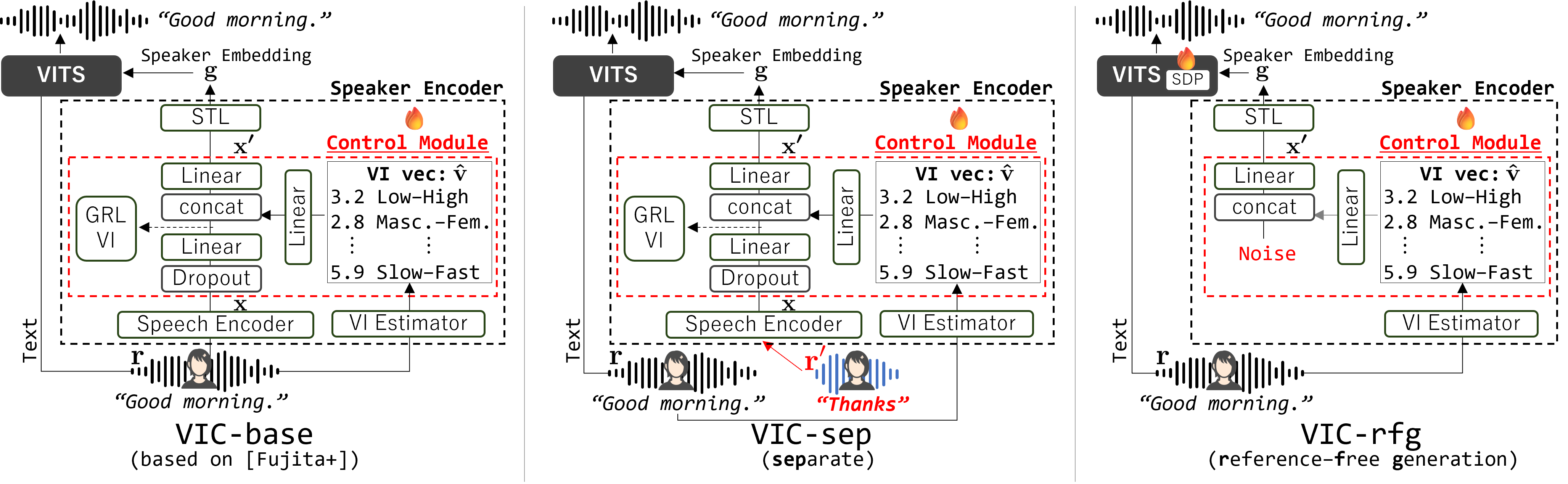
Fig. 1: Overview of the VITS-based VIC systems (base, dis, and srf) and the Qwen3-TTS prompt-based inference pipeline.
Methods:
- VIC-base (a) Baseline: [1] adapted to VITS. A single reference utterance provides both speaker identity and target VI.
- VIC-dis (b) Proposed method: mitigates impression leakage in (a) by using two distinct utterances for speaker identity and target VI during training.
- VIC-srf (c) Proposed method: removes the reference audio dependency in (a) by generating speaker embeddings solely from the target VI.
- QVD-z QVD-f (d) Qwen3-TTS [3] (LLM-based TTS) with VI control via natural language prompts. QVD-z uses the zero-shot VoiceDesign model; QVD-f uses a model fine-tuned with VI prompts.
Audio Demos for speaker 8555
Each row corresponds to one VI dimension. Use the slider to set the modulation level (-3 to +3), then click a method button to play.
| VI | Modulation Level |
|---|
Audio Demos for speaker 1089
Each row corresponds to one VI dimension. Use the slider to set the modulation level (-3 to +3), then click a method button to play.
| VI | Modulation Level |
|---|
LLM-generated Voice Impressions (speaker 8555)
Following the methodology of [1], an LLM (Gemini 2.5 Pro) generates target VI values for a given speaking style, based on speaker 8555's neutral VI. The VITS-based methods (VIC-base, dis, srf) then synthesize speech from these VI values.
| Target Style | Audio Samples & Details |
|---|---|
| Neutral |
|
Show neutral VIsNeutral VIs |
|
| Sleepy |
|
Show Prompt & LLM OutputPrompt to LLMLLM Output |
|
| Urgent, attention grabbing |
|
Show Prompt & LLM OutputPrompt to LLMLLM Output |
References
[1] K. Fujita, et al., "Voice Impression Control in Zero-Shot TTS", Interspeech 2025.
[2] Y. Koizumi, et al., "LibriTTS-R: Restoration of a Large-Scale Multi-Speaker TTS Corpus", Interspeech 2023.
[3] H. Hu, et al., "Qwen3-TTS Technical Report", arXiv:2601.15621, 2026.